

Why use Jobs and not Bare Pods?
Why use Jobs and not Bare Pods?
Why does Kubernetes have Jobs anyway? Can't plain Pods do the trick?



Programming note: Sorry for the unplanned pause in recent weeks. Natan’s wife is expecting soon, but we’re lining up guest posts to cover the absence!
Let’s start with the obvious:
Some workloads should run continuously - e.g. an HTTP server
Some tasks need to just run once until completion - e.g. a single pod that runs a one-off task
But why does Kubernetes need Jobs for one-off tasks. Couldn’t regular Pods do the trick?
Running one off-tasks using Pods without Jobs
In a world without Jobs, you would do this:
Set spec.restartPolicy to either OnFailure or Never depending on your desired behaviour.
Make sure containers set proper exit codes for Success/Failure.
All these options already exist in Kubernetes today. So what’s missing here that Jobs provide?
The Kubernetes Philosophy
Before diving into specific features that Jobs add, let’s speak about design philosophies. Kubernetes is very much about composability and simplicity.
Now wait. Before you reply to this email and tell me that Kubernetes is crazy complex, stop and think about it. When you consider everything that Kubernetes can do - and that so much of the world runs on it - then it’s honestly really simple for the stuff it can do.
The secret to that simplicity is composability. Every Kubernetes primitive is fairly simple and easy to understand. You can understand Pods independent of Deployments. You can deploy workloads to Kubernetes as a user without understanding kubelet or the APIServer.
The abstractions in Kubernetes are pretty damn good. They manage to abstract complexity away, without limiting the use case.
I’ll write more on this another time, for now back to Jobs.
What can Jobs do that Pods can’t?
Let’s start with a screenshot of a failed Kubernetes Job:
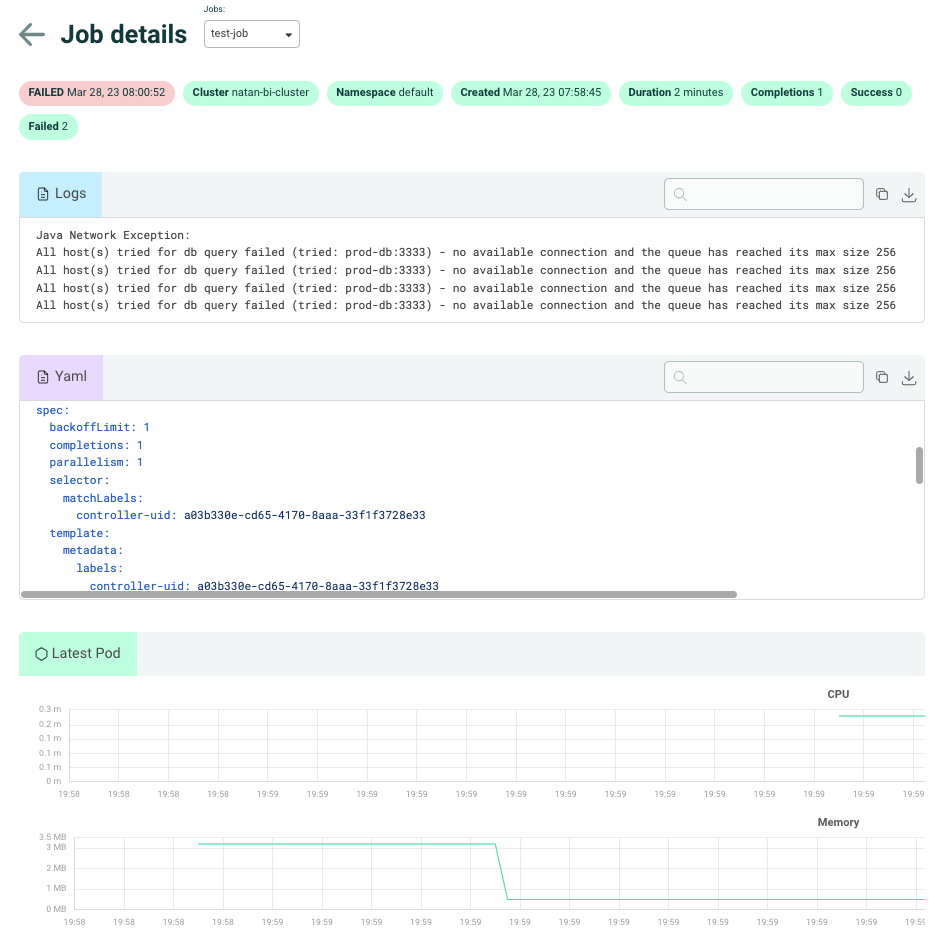
Clearly, this Job is a regular Pod, with a very thin layer wrapping it. The template that appears in the YAML spec is a PodSpecTemplate.
So what do Jobs add?
Stability in case of NodeFailures: “The Job object will start a new Pod if the first Pod fails or is deleted (for example due to a node hardware failure or a node reboot).”
Better retry mechanisms: You can specify exactly how many times a Pod is allowed to fail and restart.
Multiple Successes: When you need a task to succeed X times total and then stop running.
Parallelism: When multiple Pods can run at the same time
Closing Notes
Did I miss something? Reply with an email.
If you’re interested in this sort of thing, we ran a webinar on KEDA ScaledJobs this week. Our friends at Classiq describe how they use ScaledJobs to run a quantum compiler farm on Kubernetes. Recording on YouTube.