
Why not DNS?
Why is KubeProxy necessary? Couldn't simple DNS records do the job?



Sorry folks, we’re going to need some extra background before we can answer this one. Let’s go.
Facts about Kubernetes networking
Each Service has a unique name (my-service).
Each pod has a unique IP (10.1.1.2).1
When you connect to a Service, you reach a pod running that service.2
In other words, the Service maps between a name (my-service) and a set of Pods, each with a unique IP (10.1.1.2 and 10.1.1.3).
If there are multiple Pods in the Service, you’ll reach one of them.
Subtle nuance: you can’t actually speak to a Service, because Services don’t exist. You can only speak to a Pod in the Service. (Likewise, you can’t shake hands with “your family”, you can only shake hands with your brother.)
Facts about DNS
DNS serves as the “phone book” for the Internet: it maps domain names like www.abc.com, to IP addresses like 172.16.205.3.
DNS load balancing is the practice of configuring a domain such that client requests to are distributed across a group of server machines.
(From the NGINX glossary)
We often associate DNS with public domains like www.abc.com, but there are private DNS servers too.
Every Kubernetes cluster has a private DNS server which maps internal names like my-service to internal IPs like 10.1.1.2.
Are Services just DNS records?
Go back in time and imagine you’re on the Kubernetes founding team. You need to implement Services. Can you do it with just DNS?
First idea: add a DNS record for my-service and point it directly at Pod IPs like 10.1.1.2.
It turns out that’s a bad idea. Before explaining why, let’s see what Kubernetes really does.
How Kubernetes Services work
More or less:3
A Service gets a DNS record like my-service.ns.svc.cluster.local
That DNS record points to a single IP, called the ClusterIP.
The ClusterIP is just a made up (virtual) IP.
The ClusterIP is not the IP of any Pod.
When you access the ClusterIP, you end up connecting to a Pod anyway.

So we have Service Name → ClusterIP → Pod IP
Not Service Name → Pod IP
Why is the indirection with ClusterIP necessary? Here’s the dirty secret.
DNS wasn’t designed for rapidly changing microservices
DNS was built for a static and slow-changing world.
Sysadmins know the pain. You update a DNS record and wait. Then you wait some more.
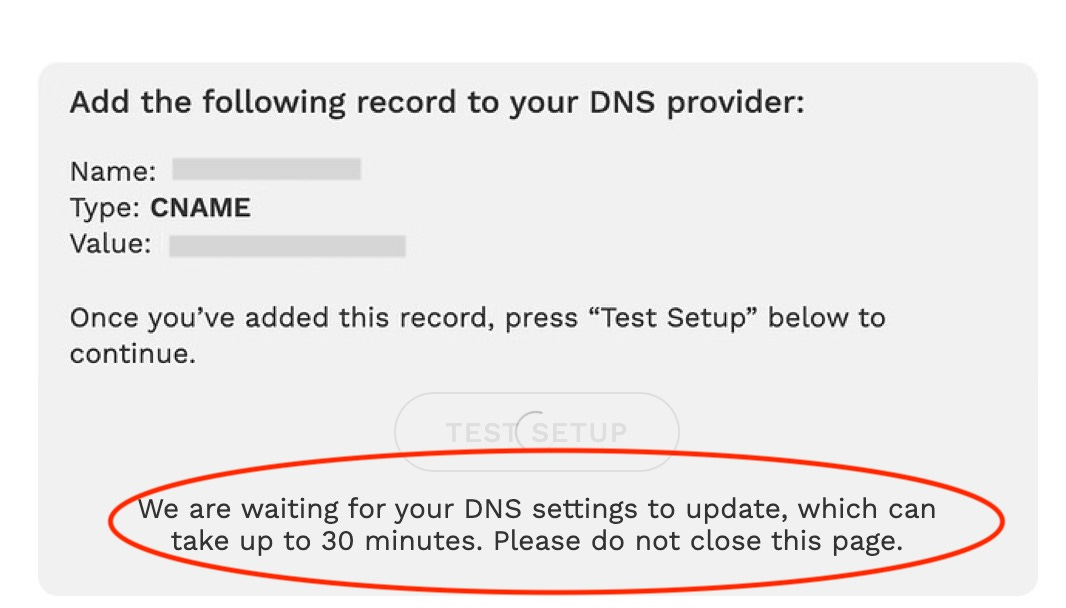
It’s not that DNS is fundamentally slow, but rather that it was designed to be cached for set periods of time.
When mapping Services to Pods, you don’t want to cache the result! The pod might not be around a moment later. Or it might be alive but failing a readiness probe, so the traffic needs to be routed elsewhere. You don’t want to use a cached result.
That said, DNS still plays an important role in Kubernetes. You typically look up Service names by DNS. That DNS is not mapped to Pod IPs directly. Rather it’s mapped to a stable IP. That IP is then routed and load-balanced based on current endpoint health using more sophisticated mechanisms.6
Pods also have unique names and each pod gets it’s own DNS record. But that’s irrelevant for this post.
We’re ignoring special types of Services like ExternalName and Headless Services.
Ignoring ExternalName/Headless Services.
There are alternatives to using KubeProxy - e.g., eBPF based routing with Cilium.
E.g. IPVS. Thank you, Adam Hamsik for pointing this out.
Thank you to Duffie Cooley for providing extensive guidance on this section.
Awesome article, would helpful to create more articles on Kubernetes networking
Thank you for your post. I can easily imagine DNS -> ClusterIP mapping if the service type is ClusterIP. Could you add some notes how it works if service type is NodePort or LB ? Thanks!